This article walks folks through the process of using the IBM FHIR Server’s helm chart with Docker Desktop Kubernetes and getting it up and running.
Tag: ibm-fhir-server
-
Upper Limit for PreparedStatement Parameters
Thanks to Lup Peng PostgreSQL JDBC Driver – Upper Limit on Parameters in PreparedStatement I was able to diagnose an upper limit:
Caused by: java.io.IOException: Tried to send an out-of-range integer as a 2-byte value: 54838 at org.postgresql.core.PGStream.sendInteger2(PGStream.java:349) at org.postgresql.core.v3.QueryExecutorImpl.sendParse(QueryExecutorImpl.java:1546) at org.postgresql.core.v3.QueryExecutorImpl.sendOneQuery(QueryExecutorImpl.java:1871) at org.postgresql.core.v3.QueryExecutorImpl.sendQuery(QueryExecutorImpl.java:1432) at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:314) ... 96 moreI had 54K parameters on my query. It turns out due to
public void sendInteger2(int val) throws IOExceptionPGStream.java has a maximum number of Short.MAX_VALUE – 32767Net for others hitting the same issue in different RDBMS systems:
- Postgres – 32767 Parameters
- IBM Db2 Limit –
Maximum number of host variable references in a dynamic SQL statement->32,76732,767 Parameters and 2,097,152 length of the text in the generated sql. Limits - Derby –
Storage capacityis the limit https://db.apache.org/derby/docs/10.14/ref/refderby.pdf
-
Bulk Data Configurations for IBM FHIR Server’s Storage Providers
As of IBM FHIR Server 4.10.2…
A colleague of mine is entering into the depths of the IBM FHIR Server’s Bulk Data feature. Each tenant in the IBM FHIR Server may specify multiple storageProviders. The default tenant is assumed, unless specified with the Http Headers
X-FHIR-BULKDATA-PROVIDERandX-FHIR-BULKDATA-PROVIDER-OUTCOME. Each tenant’s configuration may mix the different providers, however each provider is only of a single type. For instance,minioisaws-s3anddefaultisfileandazisazure-blob.Note, type
httpis only applicable to$importoperations. Export is only supported with s3, azure-blob and file.File Storage Provider Configuration
The
filestorage provider uses a directory local to the IBM FHIR Server. The fileBase is an absolute path that must exist. Each import inputUrl is a relative path from the fileBase. The File Provider is available for both import and export. Authentication is not supported.{ "__comment": "IBM FHIR Server BulkData - File Storage configuration", "fhirServer": { "bulkdata": { "__comment" : "The other bulkdata configuration elements are skipped", "storageProviders": { "default": { "type": "file", "fileBase": "/opt/wlp/usr/servers/fhir-server/output", "disableOperationOutcomes": true, "duplicationCheck": false, "validateResources": false, "create": false } } } } }An example request is:
{ "resourceType": "Parameters", "id": "30321130-5032-49fb-be54-9b8b82b2445a", "parameter": [ { "name": "inputSource", "valueUri": "https://my-server/source-fhir-server" }, { "name": "inputFormat", "valueString": "application/fhir+ndjson" }, { "name": "input", "part": [ { "name": "type", "valueString": "AllergyIntolerance" }, { "name": "url", "valueUrl": "r4_AllergyIntolerance.ndjson" } ] }, { "name": "storageDetail", "valueString": "file" } ] }HTTPS Storage Provider Configuration
The
httpstorage provider uses a set of validBaseUrls to confirm $import inputUrl is acceptable. The Https Provider is available for import. Authentication is not supported.{ "__comment": "IBM FHIR Server BulkData - Https Storage configuration (Import only)", "fhirServer": { "bulkdata": { "__comment" : "The other bulkdata configuration elements are skipped", "storageProviders": { "default": { "type": "https", "__comment": "The whitelist of valid base urls, you can always disable", "validBaseUrls": [], "disableBaseUrlValidation": true, "__comment": "You can always direct to another provider", "disableOperationOutcomes": true, "duplicationCheck": false, "validateResources": false } } } } }An example request is:
{ "resourceType": "Parameters", "id": "30321130-5032-49fb-be54-9b8b82b2445a", "parameter": [ { "name": "inputSource", "valueUri": "https://my-server/source-fhir-server" }, { "name": "inputFormat", "valueString": "application/fhir+ndjson" }, { "name": "input", "part": [ { "name": "type", "valueString": "AllergyIntolerance" }, { "name": "url", "valueUrl": "https://validbaseurl.com/r4_AllergyIntolerance.ndjson" } ] }, { "name": "storageDetail", "valueString": "https" } ] }Azure Storage Provider Configuration
The
azure-blobstorage provider uses a connection string from the Azure Blob configuration. The bucketName is the blob storage name. The azure-blob provider supports import and export. Authentication and configuration are built into the Connection string."__comment": "IBM FHIR Server BulkData - Azure Blob Storage configuration", "fhirServer": { "bulkdata": { "__comment" : "The other bulkdata configuration elements are skipped", "storageProviders": { "default": { "type": "azure-blob", "bucketName": "fhirtest", "auth": { "type": "connection", "connection": "DefaultEndpointsProtocol=https;AccountName=fhirdt;AccountKey=ABCDEF==;EndpointSuffix=core.windows.net" }, "disableBaseUrlValidation": true, "disableOperationOutcomes": true } } } } }```An example request is:
{ "resourceType": "Parameters", "id": "30321130-5032-49fb-be54-9b8b82b2445a", "parameter": [ { "name": "inputSource", "valueUri": "https://my-server/source-fhir-server" }, { "name": "inputFormat", "valueString": "application/fhir+ndjson" }, { "name": "input", "part": [ { "name": "type", "valueString": "AllergyIntolerance" }, { "name": "url", "valueUrl": "r4_AllergyIntolerance.ndjson" } ] }, { "name": "storageDetail", "valueString": "azure-blob" } ] }S3 Storage Provider Configuration
The
aws-s3storage provider supports import and export. The bucketName, location, auth style (hmac, iam), endpointInternal, endpointExternal are separate values in the configuration. Note, enableParquet is obsolete.{ "__comment": "IBM FHIR Server BulkData - AWS/COS/Minio S3 Storage configuration", "fhirServer": { "bulkdata": { "__comment" : "The other bulkdata configuration elements are skipped", "storageProviders": { "default": { "type": "aws-s3", "bucketName": "myfhirbucket", "location": "us-east-2", "endpointInternal": "https://s3.us-east-2.amazonaws.com", "endpointExternal": "https://myfhirbucket.s3.us-east-2.amazonaws.com", "auth": { "type": "hmac", "accessKeyId": "AKIAAAAF2TOAAATMAAAO", "secretAccessKey": "mmmUVsqKzAAAAM0QDSxH9IiaGQAAA" }, "enableParquet": false, "disableBaseUrlValidation": true, "exportPublic": false, "disableOperationOutcomes": true, "duplicationCheck": false, "validateResources": false, "create": false, "presigned": true, "accessType": "host" } } } } }An example request is:
{ "resourceType": "Parameters", "id": "30321130-5032-49fb-be54-9b8b82b2445a", "parameter": [ { "name": "inputSource", "valueUri": "https://my-server/source-fhir-server" }, { "name": "inputFormat", "valueString": "application/fhir+ndjson" }, { "name": "input", "part": [ { "name": "type", "valueString": "AllergyIntolerance" }, { "name": "url", "valueUrl": "r4_AllergyIntolerance.ndjson" } ] }, { "name": "storageDetail", "valueString": "aws-s3" } ] }Note, you can exchange aws-s3 and ibm-cos as the parameter.where(name=’storageDetail’). These are treated interchangeably.
There are lots of configurations that are possible, I hope this helps you.
-
GitHub Actions: Concurrency Control
My team uses GitHub Actions 18 in total jobs across about 12 workflows. When we get multiple pull requests we end up driving contention on the workflows and resources we use. I ran across concurrency control for the workflows.
To take advantage of concurrency control add this snippet to the bottom of your pull request workflow:
concurrency: group: audit-${{ github.event.pull_request.number || github.sha }} cancel-in-progress: trueWhen you stack the commits you end up with this warning, and the prior job is stopped:
e2e-db2-with-bulkdata (11) Canceling since a higher priority waiting request for 'integration-3014' exists -
Tracing the IBM FHIR Server file access on MacOSX
If you want to trace the file access of the IBM FHIR Server, you can use
fs_usageusingsudo.- Find the Server
PS=$(ps -ef | grep -i fhir-server | grep -v grep | awk '{print $2}') sudo fs_usage -w ${PS} | grep -i json- Check what files are used
$ sudo fs_usage -w ${PS} | tee out.log | grep -i json 12:11:02.328326 stat64 config/default/fhir-server-config.json 0.000023 java.2179466 12:11:02.328342 stat64 config/default/fhir-server-config.json 0.000008 java.2179466 12:11:02.328360 stat64 config/default/fhir-server-config.json 0.000008 java.2179466 12:11:02.328368 stat64 config/default/fhir-server-config.json 0.000005 java.2179466 12:11:02.332330 stat64 config/default/fhir-server-config.json 0.000020 java.2179466 12:11:02.332437 open F=109 (R___________) config/default/fhir-server-config.json 0.000085 java.2179466 12:11:02.350576 stat64 config/default/fhir-server-config.json 0.000016 java.2179466You can then see what operations are executed on the fhir-server-config.json or any other file the server accesses
Reference
-
Using Docker and Kafka with IBM FHIR Server Audit for Testing
Thie attached GIST is a package of Kubernetes yaml files and Java code to test locally with Docker/Kubernetes with the IBM FHIR Server.
You’ll want to kubectl apply -f <filename> for each of the files.
Then apply the fhir-server-config-snippet.json to your fhir-server-config.json
And run
kubectl config use-context docker-desktop
kubectl -n fhir-cicd-ns port-forward kafka-0 9092Thanks to https://github.com/d1egoaz/minikube-kafka-cluster for the inspiration.
-
Using the HL7 FHIR® Da Vinci Health Record Exchange $member-match operation in IBM FHIR Server
HL7 FHIR® Da Vinci Health Record Exchange (HREX) is an FHIR Implementation Guide at version 0.2.0 – STU R1 – 2nd ballot. The HREX Implementation Guide is a foundational guide for all of the Da Vinci guides which support US payer, provider, member and HIPAA covered entity data exchange. The guide defines "FHIR profiles, operations" and depends on HL7 FHIR® US Core Implementation Guide STU3 Release 3.1.0. In an issue, I implemented this profile and operation.
As members (Patient) move from one plan (Coverage) to another plan (Coverage) or provider (Provider). To faciliates this exchange across boundaries, HREX introduces the $member-match operation which allows one health plan to retrieve a unique identifier for a member from another health plan using a member’s demographic and coverage information. This identifier can then be used to perform subsequent queries and operations. Members implementing a deterministic match require a match on member id or subscriber id at a minimum.
The IBM FHIR Server team has implemented the HREX Implementation Guide and Operation as two modules:
fhir-ig-davinci-hrexHREX 0.2.0 Implementation Guide andfhir-operation-member-match. The operation depends onfhir-ig-us-coreUS Core 3.1.1. Note, in themainbranch thefhir-ig-us-coresupports 3.1.1 and 4.0.0. These three modules are to be released to Maven Central when the next version is tagged.The
$member-matchoperation executes on the Resource Type –Patient/$member-match. The operation implements the IBM FHIR Server Extended Operation framework using the Java Service Loader.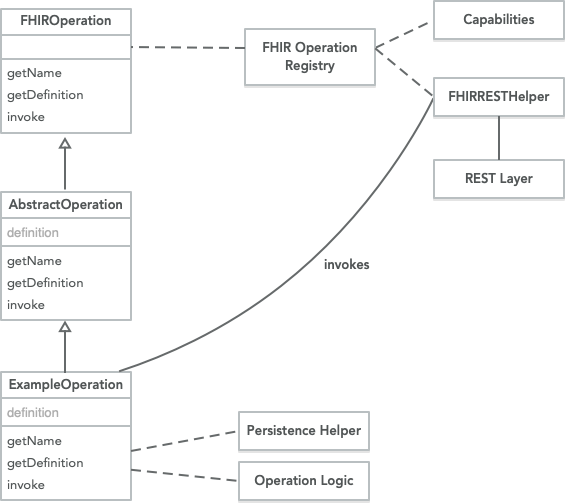
The
$member-matchprovides a default strategy to execute strategy executes a series of Searches on the local FHIR Server to find a Patient on the system with a Patient and Coverage (to-match). The strategy is extensible by extending the strategy.
MemberMatch Framework If the default strategy is not used, the Java Service Loader must be used by the new strategy. To register a JAR,
META-INF/services/com.ibm.fhir.operation.davinci.hrex.provider.strategy.MemberMatchStrategythe file must point to the package and class that implementsMemberMatchStrategy. Alternatively,AbstractMemberMatchorDefaultMemberMatchStrategymay be used as a starting point.For implementers, there is an existing
AbstractMemberMatchwhich provides a template and series of hooks to extend:MemberMatchResultimplements a light-weight response which gets translated to Output Parameters or OperationOutcomes if there is no match or multiple matches.More advanced processing of the input and validation is shown in
DefaultMemberMatchStrategywhich processes the input resources to generate SearchParameter values to query the local IBM FHIR Server.It’s highly recommended to extend the
defaultimplementation and override the getMemberMatchIdentifier for the strategy:The
$member-matchoperation is configured for each tenant using the respective fhir-server-config.json. The configuration is rooted under the pathfhirServer/operations/membermatch.Name Default Description enabled true Enables or Disable the MemberMatch operation for the tenant strategy default The key used to identify the MemberMatchStrategythat is loaded using the Java Service LoaderextendedProps true Used by custom MemberMatchStrategy implementations { "__comment": "", "fhirServer": { "operations": { "membermatch": { "enabled": true, "strategy": "default", "extendedProps": { "a": "b" } } } } }Recipe
- Prior to 4.10.0, build the Maven Projects and the Docker Build. You should see
[INFO] BUILD SUCCESSafter each Maven build, anddocker.io/ibmcom/ibm-fhir-server:latestwhen the Docker build is successful.
mvn clean install -f fhir-examples -B -DskipTests -ntp mvn clean install -f fhir-parent -B -DskipTests -ntp docker build -t ibmcom/ibm-fhir-server:latest fhir-install- Create a temporary directory for the dependencies that we’ll mount to
userlib/, so it looks at:
userlib\ fhir-ig-us-core-4.10.0.jar fhir-ig-davinci-hrex-4.10.0.jar fhir-operation-member-match-4.10.0.jarexport WORKSPACE=~/git/wffh/2021/fhir mkdir -p ${WORKSPACE}/tmp/userlib cp -p conformance/fhir-ig-davinci-hrex/target/fhir-ig-davinci-hrex-4.10.0-SNAPSHOT.jar ${WORKSPACE}/tmp/userlib/ cp -p conformance/fhir-ig-us-core/target/fhir-ig-us-core-4.10.0-SNAPSHOT.jar ${WORKSPACE}/tmp/userlib/ cp -p operation/fhir-operation-member-match/target/fhir-operation-member-match-4.10.0-SNAPSHOT.jar ${WORKSPACE}/tmp/userlib/Note, the use of snapshot as these are not yet released.
- Download the fhir-server-config.json.
curl -L -o fhir-server-config.json \ https://raw.githubusercontent.com/IBM/FHIR/main/fhir-server/liberty-config/config/default/fhir-server-config.json % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 8423 100 8423 0 0 40495 0 --:--:-- --:--:-- --:--:-- 40301- Start the Docker container, and capture the container id. It’s going to take a few moments to start up as it lays down the test database.
docker run -d -p 9443:9443 -e BOOTSTRAP_DB=true \ -v $(pwd)/fhir-server-config.json:/config/config/default/fhir-server-config.json \ -v ${WORKSPACE}/tmp/userlib:/config/userlib/ \ ibmcom/ibm-fhir-server:latest 4334334a3a6ad395c4b600e14c8563d7b8a652de1d3fdf14bc8aad9e6682cc02- Check the logs until you see:
docker logs 4334334a3a6ad395c4b600e14c8563d7b8a652de1d3fdf14bc8aad9e6682cc02 ... [6/16/21, 15:31:34:533 UTC] 0000002a FeatureManage A CWWKF0011I: The defaultServer server is ready to run a smarter planet. The defaultServer server started in 17.665 seconds.- Download and update the Sample Data
curl -L 'https://raw.githubusercontent.com/IBM/FHIR/main/conformance/fhir-ig-davinci-hrex/src/test/resources/JSON/020/Parameters-member-match-in.json' \ -o Parameters-member-match-in.json- Split the resource out from the sample:
cat Parameters-member-match-in.json | jq -r '.parameter[0].resource' > Patient.json cat Parameters-member-match-in.json | jq -r '.parameter[1].resource' > Coverage.json- Load the Sample Data bundle to the IBM FHIR Server
curl -k --location --request PUT 'https://localhost:9443/fhir-server/api/v4/Patient/1' \ --header 'Content-Type: application/fhir+json' \ --header 'Prefer: return=representation' \ --user "fhiruser:${DUMMY_PASSWORD}" \ --data-binary "@Patient.json" curl -k --location --request PUT 'https://localhost:9443/fhir-server/api/v4/Coverage/9876B1' \ --header 'Content-Type: application/fhir+json' \ --header 'Prefer: return=representation' \ --user "fhiruser:${DUMMY_PASSWORD}" \ --data-binary "@Coverage.json"Note, DUMMY_PASSWORD should be previously set to your server’s password.
- Execute the Member Match
curl -k --location --request POST 'https://localhost:9443/fhir-server/api/v4/Patient/$member-match' \ --header 'Content-Type: application/fhir+json' \ --header 'Prefer: return=representation' \ --user "fhiruser:${DUMMY_PASSWORD}" \ --data-binary "@Parameters-member-match-in.json" -o response.jsonWhen you execute the operation, it runs two visitors across the Parameters input to generate searches against the persistence store:
-
DefaultMemberMatchStrategy.MemberMatchPatientSearchCompiler – Enables the Processing of a Patient Resource into a MultivaluedMap, which is subsequently used for the Search Operation. Note there are no SearchParameters for us-core-race, us-core-ethnicity, us-core-birthsex these elements in the US Core Patient profile. The following fields are combined in a Search for the Patient:
- Patient.identifier - Patient.name - Patient.telecom - Patient.gender - Patient.birthDate - Patient.address - Patient.communication -
DefaultMemberMatchStrategy.MemberMatchCovergeSearchCompiler Coverage is a bit unique here. It’s the CoverageToMatch – details of prior health plan coverage provided by the member, typically from their health plan coverage card and has dubious provenance. The following fields are combined in a Search for the Coverage.
- Coverage.identifier - Coverage.beneficiary - Coverage.payor - Coverage.subscriber - Coverage.subscriberId
Best wishes with MemberMatch.
- Prior to 4.10.0, build the Maven Projects and the Docker Build. You should see
-
Checking fillfactor for Postgres Tables
My teammate implemented Adjust PostgreSQL fillfactor for tables involving updates #1834, which adjusts the amount of data in each storefile.
Per Cybertec,
fillfactoris important to "INSERT operations pack table pages only to the indicated percentage; the remaining space on each page is reserved for updating rows on that page. This gives UPDATE a chance to place the updated copy of a row on the same page as the original, which is more efficient than placing it on a different page." Link as such my teammate implemented in a PR a change to adjust the fillfactor to co-locate INSERT/UPDATES into the same space.Query
If you want to check your fillfactor settings, you can can check the
pg_classadmin table to see your settings using the following scripts:SELECT pc.relname as "Table Name", pc.reloptions As "Settings on Table", pc.relkind as "Table Type" FROM pg_class AS pc INNER JOIN pg_namespace AS pns ON pns.oid = pc.relnamespace WHERE pns.nspname = 'test1234' AND pc.relkind = 'r';Note
- relkind represents the object type char
ris a table. A good reference is the following snippet:relkind char r = ordinary table, i = index, S = sequence, v = view, m = materialized view, c = composite type, t = TOAST table, f = foreign table nspnameis the schema you are checking for the fillfactor values.
Results
You see the value:
basic_resources,{autovacuum_vacuum_scale_factor=0.01,autovacuum_vacuum_threshold=1000,autovacuum_vacuum_cost_limit=2000,fillfactor=90},'r'References
- relkind represents the object type char
-
Job and Bulk Data APIs
Here are some short cut APIs for Open Liberty API and IBM FHIR Server’s batch feature.
-
IBM Digital Developer Conference: Hybrid Cloud – Integrating Healthcare Data in a Serverless World
My lab is now live and available on the IBM Digital Developer Conference. In my session, developers integrate a healthcare data application using IBM FHIR Server with OpenShift serverless, to create and respond to actual healthcare scenarios.
The lab materials Link to the lab material https://prb112.github.io/healthcare-serverless/ and you need to sign up for the lab using the following instructions.
Signing up for the Lab
To get access to the lab environment, follow the following instructions:
1. Get added to the IBM Cloud account “DEGCLOUD” using the following app:– https://account-invite.mybluemix.net/
– Enter Lab key: welcome
– Enter IBM ID: the email you used to sign up for the Digital Developer Conference
2. You will then get an invite message in your email which you must accept to continue. It doesn’t matter if you see an “oops” message here.
3. Then, you can use the following app to get access to a cluster.
– Open Link https://ddc-healthcare-lab.mybluemix.net
– Enter Lab key: oslab
– Enter IBM ID: The email you used to create your IBM Cloud account
To jump right to the session you can go right to the IBM website https://developer.ibm.com/conferences/digital-developer-conference-hybrid-cloud/track-5-labs/s2-healthcare-data-serverless/
Video of the Walk Through