HL7 FHIR® Da Vinci Health Record Exchange (HREX) is an FHIR Implementation Guide at version 0.2.0 – STU R1 – 2nd ballot. The HREX Implementation Guide is a foundational guide for all of the Da Vinci guides which support US payer, provider, member and HIPAA covered entity data exchange. The guide defines "FHIR profiles, operations" and depends on HL7 FHIR® US Core Implementation Guide STU3 Release 3.1.0. In an issue, I implemented this profile and operation.
As members (Patient) move from one plan (Coverage) to another plan (Coverage) or provider (Provider). To faciliates this exchange across boundaries, HREX introduces the $member-match operation which allows one health plan to retrieve a unique identifier for a member from another health plan using a member’s demographic and coverage information. This identifier can then be used to perform subsequent queries and operations. Members implementing a deterministic match require a match on member id or subscriber id at a minimum.
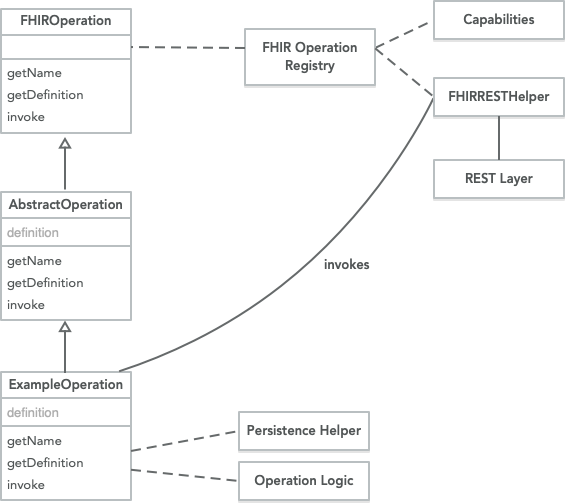
The $member-match operation executes on the Resource Type – Patient/$member-match. The operation implements the IBM FHIR Server Extended Operation framework using the Java Service Loader.
The $member-match provides a default strategy to execute strategy executes a series of Searches on the local FHIR Server to find a Patient on the system with a Patient and Coverage (to-match). The strategy is extensible by extending the strategy.
MemberMatch Framework
If the default strategy is not used, the Java Service Loader must be used by the new strategy. To register a JAR, META-INF/services/com.ibm.fhir.operation.davinci.hrex.provider.strategy.MemberMatchStrategy the file must point to the package and class that implements MemberMatchStrategy. Alternatively, AbstractMemberMatch or DefaultMemberMatchStrategy may be used as a starting point.
For implementers, there is an existing AbstractMemberMatch which provides a template and series of hooks to extend:
More advanced processing of the input and validation is shown in DefaultMemberMatchStrategy which processes the input resources to generate SearchParameter values to query the local IBM FHIR Server.
It’s highly recommended to extend the default implementation and override the getMemberMatchIdentifier for the strategy:
The $member-match operation is configured for each tenant using the respective fhir-server-config.json. The configuration is rooted under the path fhirServer/operations/membermatch.
Name
Default
Description
enabled
true
Enables or Disable the MemberMatch operation for the tenant
strategy
default
The key used to identify the MemberMatchStrategy that is loaded using the Java Service Loader
extendedProps
true
Used by custom MemberMatchStrategy implementations
Prior to 4.10.0, build the Maven Projects and the Docker Build. You should see [INFO] BUILD SUCCESS after each Maven build, and docker.io/ibmcom/ibm-fhir-server:latest when the Docker build is successful.
curl -L -o fhir-server-config.json \
https://raw.githubusercontent.com/IBM/FHIR/main/fhir-server/liberty-config/config/default/fhir-server-config.json
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 8423 100 8423 0 0 40495 0 --:--:-- --:--:-- --:--:-- 40301
Start the Docker container, and capture the container id. It’s going to take a few moments to start up as it lays down the test database.
docker logs 4334334a3a6ad395c4b600e14c8563d7b8a652de1d3fdf14bc8aad9e6682cc02
...
[6/16/21, 15:31:34:533 UTC] 0000002a FeatureManage A CWWKF0011I: The defaultServer server is ready to run a smarter planet. The defaultServer server started in 17.665 seconds.
When you execute the operation, it runs two visitors across the Parameters input to generate searches against the persistence store:
DefaultMemberMatchStrategy.MemberMatchPatientSearchCompiler – Enables the Processing of a Patient Resource into a MultivaluedMap, which is subsequently used for the Search Operation. Note there are no SearchParameters for us-core-race, us-core-ethnicity, us-core-birthsex these elements in the US Core Patient profile. The following fields are combined in a Search for the Patient:
DefaultMemberMatchStrategy.MemberMatchCovergeSearchCompiler Coverage is a bit unique here. It’s the CoverageToMatch – details of prior health plan coverage provided by the member, typically from their health plan coverage card and has dubious provenance. The following fields are combined in a Search for the Coverage.
Per Cybertec, fillfactor is important to "INSERT operations pack table pages only to the indicated percentage; the remaining space on each page is reserved for updating rows on that page. This gives UPDATE a chance to place the updated copy of a row on the same page as the original, which is more efficient than placing it on a different page." Link as such my teammate implemented in a PR a change to adjust the fillfactor to co-locate INSERT/UPDATES into the same space.
Query
If you want to check your fillfactor settings, you can can check the pg_class admin table to see your settings using the following scripts:
SELECT
pc.relname as "Table Name",
pc.reloptions As "Settings on Table",
pc.relkind as "Table Type"
FROM pg_class AS pc
INNER JOIN pg_namespace AS pns
ON pns.oid = pc.relnamespace
WHERE pns.nspname = 'test1234'
AND pc.relkind = 'r';
Note
relkind represents the object type char r is a table. A good reference is the following snippet:
relkind char r = ordinary table, i = index, S = sequence, v = view, m = materialized view, c = composite type, t = TOAST table, f = foreign table
nspname is the schema you are checking for the fillfactor values.
If you need to push changes back to GitHub, I recommend you checkout your code to a working sub folder and build in that subfolder, and copy the artifacts back to another subfolder and then push those changes (after a git add and commit with signature back to git)
Triggering GH Pages Build
In my build and release process, I generate my own website artifacts. I then need to call the API to trigger the GH Pages workflow as it is not automatically triggered by pushing the artifacts directly to the gh-pages branch. This trick starts the deployment of the branch to the gh-pages environment. It uses curl and the git hubs api.
Grabbing the Current Tag
I found this helpful to grab the tag and inject it into the Git Hub Environment variables in subsequent Workflow Job steps.
Conditionally Skip based on a Label
You should be able to skip your workflow at any given point, and you can add a conditional to skip, for instance ci-skip which should be a label in your repo.
Capture your logs and Upload no matter what
Workflows are designed to skip dependent steps on failure, Step B fails because Step A failed. It’s worth adding at the end of your workflow a step to gather any debug logs and pack them up, upload in all conditions.
The condition is set with if: always().
Lock your ‘uses’ workflow versions
Lock in your workflow’s uses on a specific version. For instance, you can lock in on action/upload-artifact or action/checkout, and use the organization/repository to check the documentation on GitHub. Here are some key Actions and the links to their Repos.
My lab is now live and available on the IBM Digital Developer Conference. In my session, developers integrate a healthcare data application using IBM FHIR Server with OpenShift serverless, to create and respond to actual healthcare scenarios.
buildah is an intriguing open source tool to build of Open Container Initiative (OCI) container images using a scripted approach versus a traditional Dockerfile. It’s fascinating and I’ve started to use podman and buildah to build my project’s images.
I picked ubi-micro as my startingn point. Per Red Hat, ubi-microis the smallest possible image excludinng the package manager and all of its dependencies which are normally included in a container image. This approach is an alternative to the current release of the IBM FHIR Server image. The following only documents my first stages with Java testing.
On Fedora, install the prerequisites.
# sudo dnf install buildah -y
Last metadata expiration check: 0:23:36 ago on Thu 02 Sep 2021 10:06:55 AM EDT.
Dependencies resolved.
=====================================================================================================================================================================
Package Architecture Version Repository Size
=====================================================================================================================================================================
Installing:
buildah x86_64 1.21.4-5.fc33 updates 7.9 M
Transaction Summary
=====================================================================================================================================================================
Install 1 Package
Total download size: 7.9 M
Installed size: 29 M
Downloading Packages:
buildah-1.21.4-5.fc33.x86_64.rpm 7.2 MB/s | 7.9 MB 00:01
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
Total 6.2 MB/s | 7.9 MB 00:01
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Installing : buildah-1.21.4-5.fc33.x86_64 1/1
Running scriptlet: buildah-1.21.4-5.fc33.x86_64 1/1
Verifying : buildah-1.21.4-5.fc33.x86_64 1/1
Installed:
buildah-1.21.4-5.fc33.x86_64
Complete!
One of the prerequisites for setting up IBM FHIR Server Bulk Data is setting up max_prepared_transactions since the IBM FHIR Server leverages Open Liberty Java Batch which uses an XA Transaction.
Update your Server Parameters max_prepared_transactions to 200 (anything non-zero is recommended to enable XA)
Click Save
Click Overview
Click Restart
Click On Activity Log
Wait until Postgres is restarted
Restart your IBM FHIR Server, and you are ready to use the Bulk Data feature.
If you don’t do the setup, you’ll see a log like the following:
[9/2/21, 1:49:38:257 UTC] [step1 partition0] com.ibm.fhir.bulkdata.jbatch.listener.StepChunkListener StepChunkListener: job[bulkexportfastjob/8/15] --- javax.transaction.RollbackException
com.ibm.jbatch.container.exception.TransactionManagementException: javax.transaction.RollbackException
at com.ibm.jbatch.container.transaction.impl.JTAUserTransactionAdapter.commit(JTAUserTransactionAdapter.java:108)
at com.ibm.jbatch.container.controller.impl.ChunkStepControllerImpl.invokeChunk(ChunkStepControllerImpl.java:656)
at com.ibm.jbatch.container.controller.impl.ChunkStepControllerImpl.invokeCoreStep(ChunkStepControllerImpl.java:795)
at com.ibm.jbatch.container.controller.impl.BaseStepControllerImpl.execute(BaseStepControllerImpl.java:295)
at com.ibm.jbatch.container.controller.impl.ExecutionTransitioner.doExecutionLoop(ExecutionTransitioner.java:118)
at com.ibm.jbatch.container.controller.impl.WorkUnitThreadControllerImpl.executeCoreTransitionLoop(WorkUnitThreadControllerImpl.java:96)
at com.ibm.jbatch.container.controller.impl.WorkUnitThreadControllerImpl.executeWorkUnit(WorkUnitThreadControllerImpl.java:178)
at com.ibm.jbatch.container.controller.impl.WorkUnitThreadControllerImpl$AbstractControllerHelper.runExecutionOnThread(WorkUnitThreadControllerImpl.java:503)
at com.ibm.jbatch.container.controller.impl.WorkUnitThreadControllerImpl.runExecutionOnThread(WorkUnitThreadControllerImpl.java:92)
at com.ibm.jbatch.container.util.BatchWorkUnit.run(BatchWorkUnit.java:113)
at com.ibm.ws.context.service.serializable.ContextualRunnable.run(ContextualRunnable.java:79)
at com.ibm.ws.threading.internal.ExecutorServiceImpl$RunnableWrapper.run(ExecutorServiceImpl.java:238)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:866)
Caused by: javax.transaction.RollbackException
at com.ibm.tx.jta.impl.TransactionImpl.stage3CommitProcessing(TransactionImpl.java:978)
at com.ibm.tx.jta.impl.TransactionImpl.processCommit(TransactionImpl.java:778)
at com.ibm.tx.jta.impl.TransactionImpl.commit(TransactionImpl.java:711)
at com.ibm.tx.jta.impl.TranManagerImpl.commit(TranManagerImpl.java:165)
at com.ibm.tx.jta.impl.TranManagerSet.commit(TranManagerSet.java:113)
at com.ibm.tx.jta.impl.UserTransactionImpl.commit(UserTransactionImpl.java:162)
at com.ibm.tx.jta.embeddable.impl.EmbeddableUserTransactionImpl.commit(EmbeddableUserTransactionImpl.java:101)
at com.ibm.ws.transaction.services.UserTransactionService.commit(UserTransactionService.java:72)
at com.ibm.jbatch.container.transaction.impl.JTAUserTransactionAdapter.commit(JTAUserTransactionAdapter.java:101)